

日本作为亚洲科技发达国家之一,拥有先进的网络基础设施和先进技术,其独立服务器在数据分析和大规模计算任务中发挥着关键作用。以下是日本独立服务器在这些领域中的应用和优势:
一、高性能计算:
强大的硬件配置: 日本独立服务器通常配备先进的处理器、大容量内存和高速存储设备,能够提供强大的计算和存储能力,满足大规模计算任务的需求。
GPU加速计算: 针对需要大规模并行计算的任务,日本独立服务器常配备GPU加速器,提供高性能的并行计算能力,加速数据分析和模拟计算过程。
集群和分布式计算: 多台日本独立服务器可以组建成集群或分布式计算环境,通过并行计算和任务分发,提高计算效率和吞吐量,应对大规模计算任务的挑战。
二、数据安全性:
严格的安全控制: 日本独立服务器提供严格的安全控制机制,包括访问控制、数据加密和身份认证等,保障数据在传输和存储过程中的安全性和保密性。
合规性和隐私保护: 日本的数据保护法律和规定较为完善,日本独立服务器严格遵守相关法规,保护用户数据的合规性和隐私权,确保数据分析过程的合法性和可靠性。
三、网络稳定性:
高速稳定的网络连接: 日本拥有先进的网络基础设施,日本独立服务器通常连接到高速稳定的国际网络,确保数据分析和计算任务能够稳定高效地进行。
灵活的网络架构: 日本独立服务器提供灵活的网络架构和带宽管理功能,用户可以根据实际需求调整网络带宽和配置,确保数据传输和计算任务的顺畅进行。
综上所述,日本独立服务器在数据分析和大规模计算任务中具有优势,通过其高性能计算能力、数据安全性和网络稳定性,为用户提供可靠的计算和数据分析环境,助力科研、商业和工程领域的发展和创新。
好主机测评广告位招租-300元/3月Linux 服务器日志统计有什么比较好的工具或开源软件
初级: syslog基中管理 + 手工编写分析脚本 + CGI输出,适合简单分析,数据量不大的场景进阶:LogStash,是一个应用程序日志、事件的传输、处理、管理和搜索的平台。 你可以用它来统一对应用程序日志进行收集管理,提供 Web 接口用于查询和统计。 个人用下来感觉它的全文检索功能最为强大,基本上你可以把它看成是splunk的开源解决方案更灵活: Flume + Hadoop + Hive,这三个都是属于Apache基金会下的项目,Flume用与收集日志,Hadoop用于分析与存储,Hive用于存放处理后的数据。 这个方案是最灵活也是最强大的,不过搭配起来需要花时间,UI要另外编写。
如何处理大量数据并发操作
大并发大数据量请求的处理方法大并发大数据量请求一般会分为几种情况:1.大量的用户同时对系统的不同功能页面进行查找,更新操作2.大量的用户同时对系统
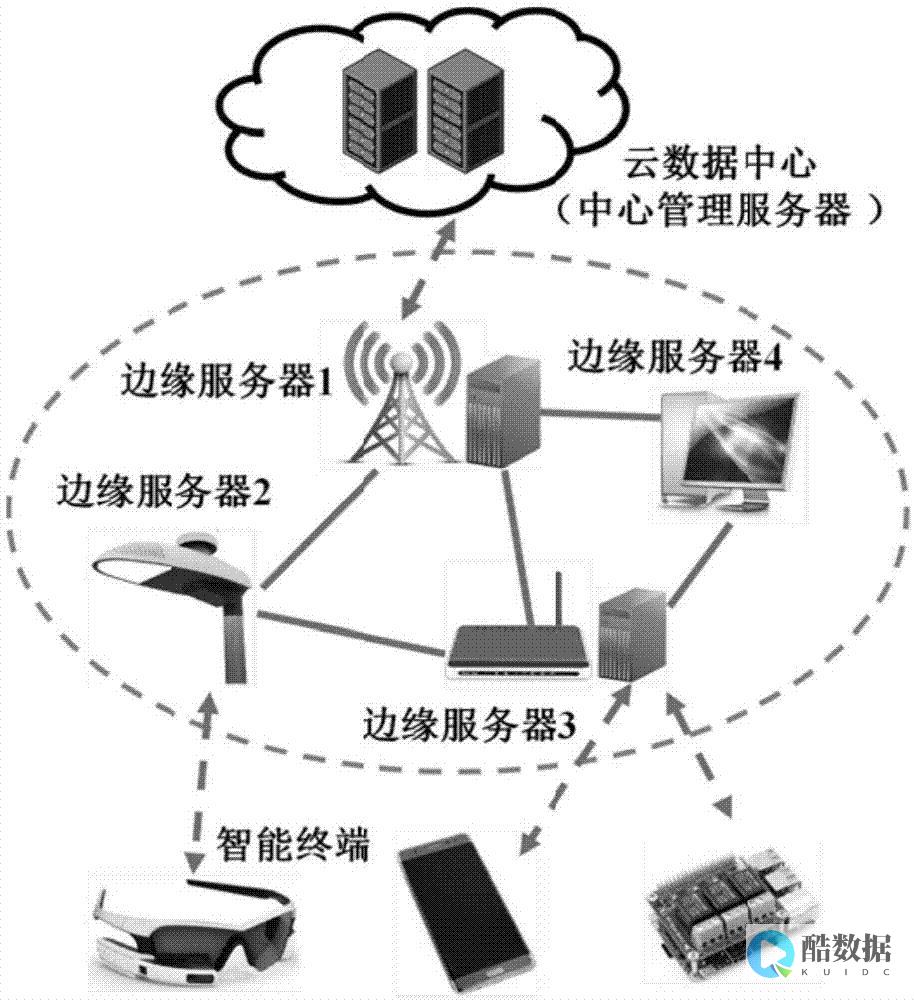
海量数据,分布式计算,并行计算 虚拟化与云计算的关系是怎样的
您好,海量数据涉及到一些方面。 我给你介绍一下第一点涉及到云存储和分布式存储。 第二点涉及到分布式计算和并行计算。 分布式计算和并行计算:并行计算偏科学领域,偏单用户,单请求,在配置多处理机的服务器下处理。 分布式计算偏多用户,多请求,涉及多台服务器多个计算单元的分布式处理。 分布式计算本身又分为两种,一种是单任务拆分,如mapreduce来实现;一种是多请求分布式调度,涉及到云计算paas还有疑问请追问没有疑问请采纳








发表评论