
随着数据量的急剧增加和信息的快速传播,模式识别和数据分类变得越来越关键。在过去,这些任务可能需要大量的时间和资源才能完成,但是随着GPU(图形处理单元)服务器的普及和发展,高性能计算变得更加容易实现。本文将讨论如何利用GPU服务器实现高效的模式识别和数据分类。
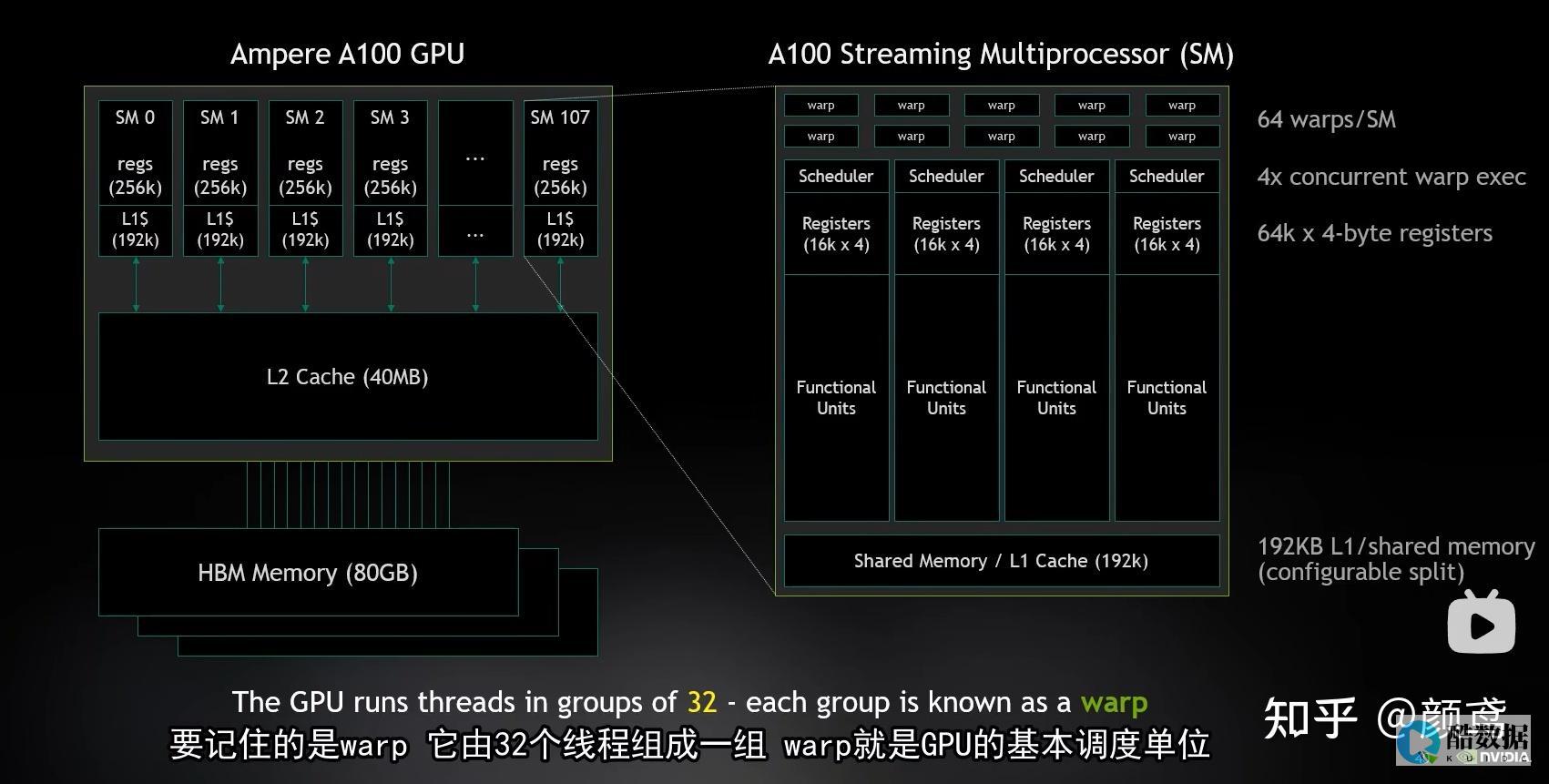
GPU服务器的优势
GPU服务器之所以受到青睐,是因为它们具有强大的并行处理能力。相比于传统的CPU(中央处理单元),GPU可以同时执行大量的计算任务,这使得它们特别适合于处理需要大量并行计算的任务,如图像处理和深度学习。通过利用GPU服务器,可以显著提高模式识别和数据分类的处理速度和效率。
优化算法
在GPU服务器上实现高效的模式识别和数据分类的关键之一是选择合适的优化算法。一些经典的算法,如支持向量机(SVM)和k最近邻(KNN),可以通过并行化和优化以适应GPU的架构。此外,还有一些专门针对GPU设计的算法,如CUDA(Compute Unified Device Architecture)库中提供的算法,可以充分发挥GPU的性能优势。
并行计算
GPU服务器的另一个优势是并行计算。通过将数据分割成小块,在多个GPU核心上同时进行计算,可以大大加快模式识别和数据分类的处理速度。并行计算还可以提高系统的吞吐量,使其能够处理更多的数据,从而进一步提高效率。
深度学习的应用
深度学习是近年来在模式识别和数据分类领域取得重大突破的技术之一。利用深度神经网络可以从大量数据中学习复杂的模式和特征,从而实现高精度的分类和识别。在GPU服务器上,深度学习模型可以通过并行计算来加速训练和推理过程,从而更快地完成模式识别和数据分类任务。
结论
通过利用GPU服务器的强大计算能力,可以实现高效的模式识别和数据分类。优化算法、并行计算和深度学习技术的应用可以进一步提高处理速度和准确性。随着技术的不断进步,我们可以期待在GPU服务器上实现更加高效的模式识别和数据分类方法的出现,从而应对日益增长的数据处理需求。
好主机测评广告位招租-300元/3月用opencv定位和识别数字如何识别呢,急求~~~~~~~~~
你的这个问题要分两步去做,首先是定位,找到你的这个正方形,然后去颜色匹配。 所以涉及了两部分代码。 扫描一个矩形区域,你的这帧图像里是不是就这么一个矩形区域,还是有别的矩形区域?黄色红色会不会在其他地方也有,这些还没交代清楚。
图像分类处理原理
1. 图像分类处理的依据图像分类处理的依据就是模式识别的过程,即通过对各类地物的遥感影像特征分析来选择特征参数,将特征空间划分为互不重叠的子空间并将图像内各个像元划分到各个子空间区,从而实现分类。 这里特征参数是指能够反映地物影像特征并可用于遥感图像分类处理的变量,如多波段图像的各个波段、多波段图像的算术/逻辑运算结果、图像变换/增强结果、图像空间结构特征等; 特征空间是指由特征变量组成的多维空间。 遥感影像中同一类地物在相同的条件下 ( 纹理、地形、光照及植被覆盖等) ,应具有相同或相似的光谱信息特征和空间信息特征,从而表现出同类地物的某种内在的相似性。 在多波段遥感的数字图像中,可以粗略地用它们在各个波段上的像元值的连线来表示其光谱信息 ( 图 4-22a) 。 在实际的多维空间中,地物的像元值向量往往不是一个点,而是呈点群分布 ( 集群) 。 同类地物的特征向量将集群在同一特征空间域,不同地物的光谱信息或空间信息特征不同,因而将集群在不同的特征的空间域 ( 图 4-22b) 。 在实际图像中,不同地物的集群还存在有交叉过渡,受图像分辨率的限制,一个像元中可能包括有若干个地物类别,即所谓 “混合像元”,因此对不同集群的区分要依据它们的统计特征来完成。 2. 图像分类处理的关键问题图像分类处理的关键问题就是按概率统计规律,选择适当的判别函数、建立合理的判别模型,把这些离散的 “集群”分离开来,并作出判决和归类。 通常的做法是,将多维波谱空间划分为若干区域 ( 子空间) ,位于同一区域内的点归于同一类。 子空间划分的标准可以概括为两类: ①根据点群的统计特征,确定它所应占据的区域范围。 例如,以每一类的均值向量为中心,规定在几个标准差的范围内的点归为一类。 ②确定类别之间的边界,建立边界函数或判别函数。 不论采取哪种标准,关键在于确定同一类别在多维波谱空间中的位置 ( 类的均值向量) 、范围 ( 协方差矩阵) 及类与类边界 ( 判别函数) 的确切数值。 按确定这些数据是否有已知训练样本 ( 样区) 为准,通常把分类技术分为监督和非监督两类。 非监督分类是根据图像数据本身的统计特征及点群的分布情况,从纯统计学的角度对图像数据进行类别划分的分类处理方法。 监督分类是根据已知类别或训练样本的模式特征选择特征参数并建立判别函数,把图像中各个像元点划归至给定类中的分类处理方法。 图 4-22 某地数字图像上主要几种地物的光谱反射比曲线和集群分布3. 监督分类与非监督分类的本质区别监督分类与非监督分类的本质区别在于有无先验知识。 非监督分类为在无分类对象先验知识的条件下,完全根据数据自身的统计规律所进行的分类; 监督分类指在先验知识( 训练样本的模式特征等先验知识) 的 “监督”之下进行分类。 非监督分类的结果可作为监督分类训练样本选择的重要参考依据,同时,监督分类中训练样本的选择需要目视解译工作者、专家的地学知识与经验作为支撑。 4. 遥感图像分类的工作流程①确定分类类别: 根据专题目的和图像数据特性确定计算机分类处理的类别数与类特征; ②选择特征参数: 选择能描述各类别的特征参数变量; ③提取分类数据: 提取各类别的训练 ( 样本) 数据; ④测定总体统计特征: 或测定训练数据的总体特征,或用聚类分析方法对特征相似的像元进行归类分析并测定其特征; ⑤分类: 用给定的分类基准对各个像元进行分类归并处理; ⑥分类结果验证: 对分类的精度与可靠性进行分析。
数字图像分析主要内容
遥感影像数字图像处理的内容主要有:1、图像恢复:即校正在成像、记录、传输或回放过程中引入的数据错误、噪声与畸变。 包括辐射校正、几何校正等;2、数据压缩:以改进传输、存储和处理数据效率;3、影像增强:突出数据的某些特征,以提高影像目视质量。 包括彩色增强、反差增强、边缘增强、密度分割、比值运算、去模糊等;4、信息提取:从经过增强处理的影像中提取有用的遥感信息。 包括采用各种统计分析、集群分析、频谱分析等自动识别与分类。 通常利用专用数字图像处理系统来实现,且依据目的不同采用不同算法和技术。









发表评论