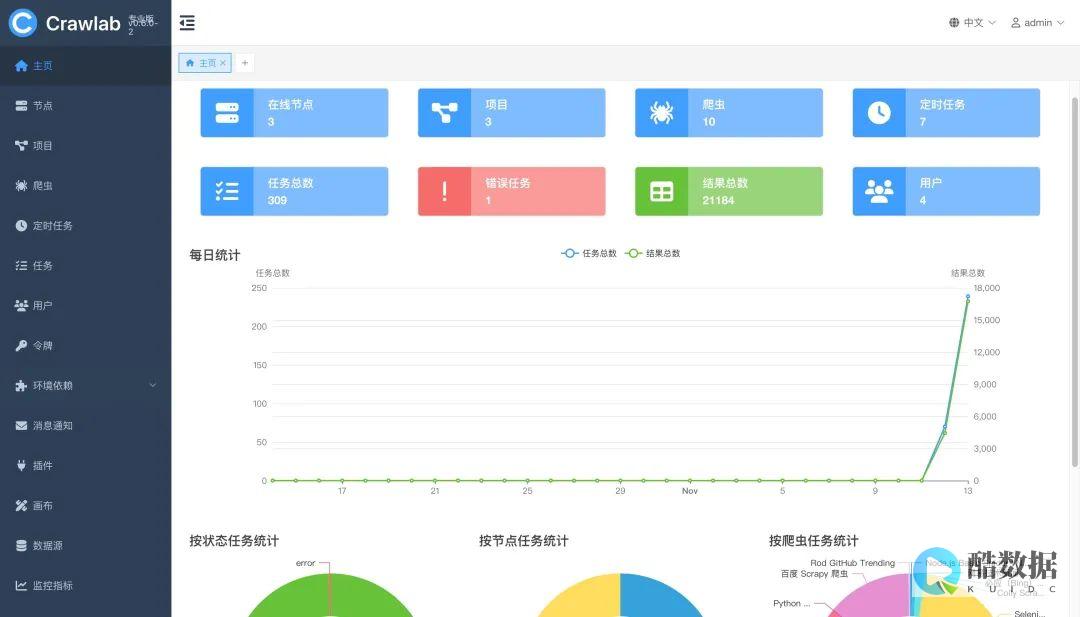
摘要:本文介绍了如何配置爬虫项目的服务器,并设置网站的反爬虫防护规则以防御爬虫攻击。
在当前互联网时代,网络数据爬取已成为获取信息的重要手段之一,无论是商业分析、市场调研还是学术研究,爬虫技术都扮演着不可或缺的角色,随之而来的是网站对于自身数据的保护需求增强,因而采取了一系列反爬虫措施来防御恶意的网络爬虫攻击,本文将深入探讨如何配置爬虫项目的服务器以及设置网站的反爬虫防护规则以防御爬虫攻击。
服务器配置
根据爬虫的复杂度和预期处理的数据量大小,选择合适的服务器配置至关重要,以下是一些基本的配置步骤和推荐:
1、 选择合适的硬件配置 :对于小规模的爬虫任务,一个具有中等配置的虚拟私人服务器(vps)通常就足够了,这种服务器一般配备有多个CPU核心、足够的RAM(建议至少8GB)和适量的存储空间(建议不低于50GB的SSD),高性能的服务器可以显著提高处理速度,同时保证稳定性。
2、 安装必要的软件和库 :确保服务器操作系统(如linux)上安装了Python和相关爬虫库(如Requests、BeautifulSoup等),这些库可以通过系统的包管理工具如apt或yum进行安装,也可以直接通过pip安装。
3、 选择爬虫框架 :Python提供了多种爬虫框架,如Scrapy、BeautifulSoup等,Scrapy是一个功能丰富、文档友好的框架,适合初学者快速上手,根据项目的具体需求选择合适的框架,并通过pip命令进行安装。
4、 创建爬虫项目 :使用选择的爬虫框架创建项目,在Scrapy中可以通过一个简单的命令行操作生成新项目的结构。
这些步骤为爬虫项目的部署提供了基础,为了保证爬虫的有效性和高效性,还需要进一步配置和优化,比如分布式爬虫的设计,这对于大规模数据抓取尤其重要。
反爬虫防护规则配置
网站管理员为了保护数据不被非法抓取,通常会设置一系列的反爬虫机制,以下是一些有效的策略:
1、 Web应用防火墙(WAF) :部署WAF是防止爬虫攻击的一种有效方式,通过配置访问规则,WAF能够识别并过滤掉恶意请求,如假冒的UserAgent、异常高的访问频率等。
2、 识别UserAgent和检查浏览器合法性 :合法的用户访问通常通过标准的浏览器进行,而爬虫可能会使用自定义的UserAgent或甚至不使用浏览器,通过校验这些信息,可以有效识别并阻止爬虫行为。
3、 限制访问频率 :人类用户的访问模式与机器明显不同,设置阈值限制短时间内的重复请求,有助于减缓或阻止自动化的爬虫活动。
综合以上策略,网站可以大幅度提高对爬虫攻击的防御能力,值得注意的是,过度的防护措施可能也会影响正常用户的访问体验,因此在制定防护规则时需要找到一个平衡点。
Q1: 如何检测我的服务器是否已被爬虫攻击?
A1: 监控服务器的访问日志是发现爬虫攻击的一种有效方法,异常的高访问量、频繁的非人类访问模式(如连续快速的请求)通常是爬虫活动的迹象,许多服务器软件和WAF提供自动的检测与报告功能,可以帮助管理员及时发现并应对爬虫攻击。
Q2: 为什么有些爬虫能绕过我的反爬虫机制?
A2: 高级的爬虫程序可能会模拟正常用户的行为,比如更改UserAgent、使用合法的浏览器头信息或甚至加载JavaScript来解析动态内容,它们可能会调整请求速度以避免触发频率限制规则,防御这类高级爬虫需要更复杂的机制,如实施行为分析或使用验证码等多重验证方法。
好主机测评广告位招租-300元/3月
急,急,急..tomcat的server.xml如何配置????
你将你的项目放在服务器的任意磁盘都可以,配置文件,在host下添加
如何设计爬虫架构
设计爬虫架构一个设计良好的爬虫架构必须满足如下需求。 (1) 分布式:爬虫应该能够在多台机器上分布执行。 (2) 可伸缩性:爬虫结构应该能够通过增加额外的机器和带宽来提高抓取速度。 (3) 性能和有效性:爬虫系统必须有效地使用各种系统资源,例如,处理器、存储空间和网络带宽。 (4) 质量:鉴于互联网的发展速度,大部分网页都不可能及时出现在用户查询中,所以爬虫应该首先抓取有用的网页。 (5) 新鲜性:在许多应用中,爬虫应该持续运行而不是只遍历一次。 (6) 更新:因为网页会经常更新,例如论坛网站会经常有回帖。 爬虫应该取得已经获取的页面的新的拷贝。 例如一个搜索引擎爬虫要能够保证全文索引中包含每个索引页面的较新的状态。 对于搜索引擎爬虫这样连续的抓取,爬虫访问一个页面的频率应该和这个网页的更新频率一致。 (7) 可扩展性:为了能够支持新的数据格式和新的抓取协议,爬虫架构应该设计成模块化的形式。
用来做网站服务器的PC配置
最好弄1U服务器机箱 以后如果不小心做大了 托管也不贵弄个酷睿7300 2G 160G的吧看着再加大点3000以下1U机箱











发表评论