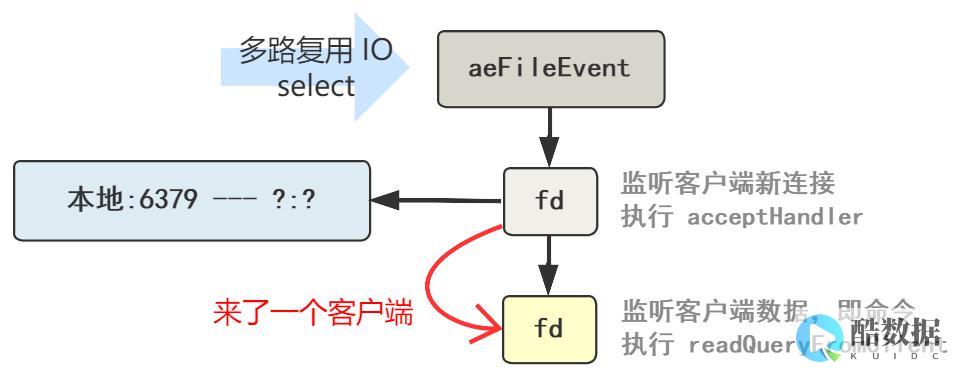
实现Redis迁移:简洁的代码实现
Redis是一种基于内存的键值数据库,它可以处理高并发的读写操作并支持多种数据结构。在实际的应用中,我们可能需要将Redis的数据迁移到新的机器上,以提高性能或者满足新的业务需求。
本文将分享一种简洁的方法来实现Redis的迁移,代码实现如下:
import redis
class RedisMigration(object):
def __init__(self, src_host, src_port, dst_host, dst_port):
self.src_r = redis.Redis(host=src_host, port=src_port)
self.dst_r = redis.Redis(host=dst_host, port=dst_port)
def migrate(self, key_prefix=None):
if key_prefix is None:
keys = self.src_r.keys()
keys = self.src_r.keys(key_prefix + ‘*’)
for key in keys:
value = self.src_r.get(key)
self.dst_r.set(key, value)
self.src_r.delete(key)
上述代码中,我们首先导入redis模块,并定义了RedisMigration类。在初始化方法中,我们分别建立了源Redis和目标Redis对象。在迁移方法migrate中,我们首先根据key_prefix条件获取源Redis中的key列表,然后依次将每个key的值从源Redis迁移到目标Redis中。我们删除源Redis中的key。使用上述代码,我们可以很快地实现Redis的迁移,甚至可以将它封装成一个命令行工具或者Web界面,以方便使用。需要注意的是,上述代码并未考虑数据量大、网络延迟等情况。在实际应用中,我们可能需要采用分批迁移、设置超时时间等方法来优化迁移过程。同时,为了保障数据的安全性,我们还需要做好备份和恢复策略。在总结中,本文介绍了一种简洁的Redis迁移方法,并给出代码实现。但迁移过程中还需要在实际应用中进行优化,以保障数据安全和迁移效率。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(www.IDC.Net)提供简单好用,价格厚道的香港/美国云 服务器 和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
用数字编码表达信息有什么好处?
数字编码信息较简洁,且有利于用计算机处理 或者代表某些不需要或不方便透露太详细信息的事物 比如某些特警或杀手组推行邮政编码是我国邮政业务、技术制度的一项重大改革。 当今,社会已进入信息时代。 时间就是生命,效率就是金钱。 而信息的价值则取决于它的传递速度。 没有速度的信息就会失去其本身的价值和应有的效益。 因此,为了适应广大用户对加快信息传递速度的需求,加快邮件的处理速度,同时,也为提高我国邮政的现代化水平,邮电部决定推行邮政编码制度。 织用数字来代表某些组织成员 …………
雕刻机上面的雕刻指令G代码是指什么意思 你可不可以简单点说 通俗点
G代码不是雕刻机上的,G代码是编程软件自动产生的代码,也就是说,刀路里的东西都是G代码表示的,只有这种G代码。 才会被雕刻机识别。 识别以后雕刻机才会按照G代码的意思完成工作,这回明白了吗
使用简单工厂模式的优点是什么?
工厂模式就相当于创建实例对象的new,我们经常要根据类Class生成实例对象,如A a=new A(). 工厂模式也是用来创建实例对象的,可能多做一些工作,但会给你系统带来更大的可扩展性和尽量少的修改量。 类Sample为例,要创建Sample的实例对象: Sample sample=new Sample();可是,实际情况是,通常我们都要在创建sample实例时做点初始化的工作,比如赋值 查询数据库等 首先,我们想到的是,可以使用Sample的构造函数,这样生成实例就写成: Sample sample=new Sample(参数); 但是,如果创建sample实例时所做的初始化工作不是象赋值这样简单的事,可能是很长一段代码,如果也写入构造函数中,那你的代码很难看了 初始化工作如果是很长一段代码,说明要做的工作很多,将很多工作装入一个方法中,相当于将很多鸡蛋放在一个篮子里,是很危险的,这也是有背于Java面向对象的原则,面向对象的封装(Encapsulation)和分派(Delegation)告诉我们,尽量将长的代码分派“切割”成每段,将每段再“封装”起来(减少段和段之间偶合联系性),这样,就会将风险分散,以后如果需要修改,只要更改每段,不会再发生牵一动百的事情。 我们需要将创建实例的工作与使用实例的工作分开, 也就是说,让创建实例所需要的大量初始化工作从Sample的构造函数中分离出去。 你想如果有多个类似的类,我们就需要实例化出来多个类。 这样代码管理起来就太复杂了。 这个时候你就可以采用工厂方法来封装这个问题。 不能再用上面简单new Sample(参数)。 还有,如果Sample有个继承如MySample, 按照面向接口编程,我们需要将Sample抽象成一个接口.现在Sample是接口,有两个子类MySample 和HisSample Sample mysample=new MySample();Sample hissample=new HisSample();采用工厂封装: public class Factory{ public static Sample creator(int which){ //getClass 产生Sample 一般可使用动态类装载装入类。 if (which==1) return new SampleA();else if (which==2) return new SampleB(); } } 那么在你的程序中,如果要实例化Sample时.就使用 Sample sampleA=(1);举个更实际的例子,比如你写了个应用,里面用到了数据库的封装,你的应用可以今后需要在不同的数据库环境下运行,可能是oracle,db2,sql server等,那么连接数据库的代码是不一样的,你用传统的方法,就不得不进行代码修改来适应不同的环境,非常麻烦,但是如果你采用工厂类的话,将各种可能的数据库连接全部实现在工厂类里面,通过你配置文件的修改来达到连接的是不同的数据库,那么你今后做迁移的时候代码就不用进行修改了。 我通常都是用xml的配置文件配置许多类型的数据库连接,非常的方便。 PS:工厂模式在这方面的使用较多。








发表评论