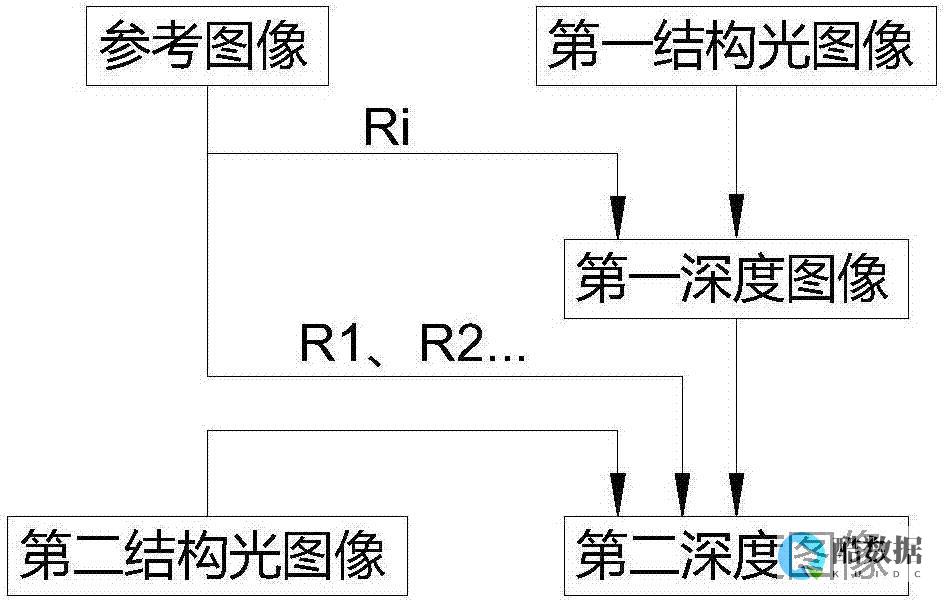
MySQL查询缓存机制是mySQL数据库中的重要机制之一,下面将为您深入分析MySQL查询缓存机制,供您参考学习之用。
MySQL缓存机制简单的说就是缓存sql文本及查询结果,如果运行相同的sql, 服务器 直接从缓存中取到结果,而不需要再去解析和执行sql。如果表更改 了,那么使用这个表的所有缓冲查询将不再有效,查询缓存值的相关条目被清空。更改指的是表中任何数据或是结构的改变,包括INSERT、UPDATE、 DELETE、TRUNCATE、ALTER TABLE、DROP TABLE或DROP>
mysql 有自己的缓存机制 ,为什么还要用Redis和memcache缓存mysql数据?
Redis和Memcache都属于NoSQL,内存性数据库相比关系型数据库的效率更高。 据我所知,Redis的读取速度是11W,写入速度是8W.这是比MySQL高很多的。
mysql innodb 怎么缓存数据的原理
1、query_cache_size=0 已经禁用了查询缓存,但表数据可能缓存了,flush tables试试,不过操作系统还有一个硬盘缓存,想跟第一次查询之前的状态一致恐怕只能每次重启 2、group by与order by不会用索引的,索引最大的用处就是减小磁盘IO,
mysql对联合索引有优化么?会自动调整顺序么?哪个版本开始优化

高效的数据库,mysql基本是首选。 良好的安全连接,自带查询解析、sql语句优化,使用读写锁(细化到行)、事物隔离和多版本并发控制提高并发,完备的事务日志记录,强大的存储引擎提供高效查询(表记录可达百万级),如果是InnoDB,还可在崩溃后进行完整的恢复,优点非常多。 即使有这么多优点,仍依赖人去做点优化,看书后写个总结巩固下,有错请指正。 完整的mysql优化需要很深的功底,大公司甚至有专门写mysql内核的,sql优化攻城狮,mysql服务器的优化,各种参数常量设定,查询语句优化,主从复制,软硬件升级,容灾备份,sql编程,需要的不是一星半点的知识与时间来掌握,作为一名像俺这样的菜鸟开发,强吃这么多消化不了也没意义:没地儿用啊,况且还有运维和dba,还不如把手头的业务写好,也就是写好点的sql,而且很多sql语句优化跟索引还是有很大关系的。 首先,mysql的查询流程大致是:mysql客户端通过协议与mysql服务器建立连接,发送查询语句,先检查查询缓存,如果命中,直接返回结果,否则进行语句解析,有一系列预处理,比如检查语句是否写正确了,然后是查询优化(比如是否使用索引扫描,如果是一个不可能的条件,则提前终止),生成查询计划,然后查询引擎启动,开始执行查询,从底层存储引擎调用API获取数据,最后返回给客户端。 怎么存数据、怎么取数据,都与存储引擎有关。 然后,mysql默认使用的BTREE索引,并且一个大方向是,无论怎么折腾sql,至少在目前来说,mysql最多只用到表中的一个索引。 mysql通过存储引擎取数据,自然跟存储引擎有很大关系,不同的存储引擎索引也不一样,如MyISAM的全文索引,即便索引叫一个名字内部组织方式也不尽相同,最常用的当然就是InnoDB了(还有完全兼容mysql的MariaDB,它的默引擎是XtraDB,跟InnoDB很像),这里写的是InnoDB引擎。 而索引的实现也跟存储引擎,按照实现方式分,InnoDB的索引目前只有两种:BTREE索引和HASH索引。 通常我们说的索引不出意外指的就是B树索引,InnoDB的BTREE索引,实际是用B+树实现的,因为在查看表索引时,mysql一律打印BTREE,所以简称为B树索引。 至于B树与B+树的区别,原谅的俺数据结构没好好学,也是需要补的地方。








发表评论